
AI at Talenom
This blog is an introduction to our new blog series. The blog series covers some interesting topics that we have faced during developing of productionized AI system. The AI system we are covering in the blog series is automatic posting of purchase invoices.
Business context
At Talenom we post 100 000 purchase invoices every week solely in Finland. As the company is expanding to other countries as well, the invoice mass will scale to whole new numbers in the near future.
Talenom has invested a lot to increase automation rate of accounting. Therefore, only a small proportion of the invoices is posted manually by humans today, automation rate being 76% at the moment.
At the first stage of automation, the human work was reduced by creating customer specific posting rules. This provided great help for automation but was not still enough for us. Using AI based approach we can enhance automation rate further and ease the maintenance work. Of course, also AI needs maintenance and training of new models but with solid MLOps flow this is minimal effort compared to effort that the accounting rules takes.
Posting as a machine learning problem
Posting of purchase invoices contains two separate machine learning problems.
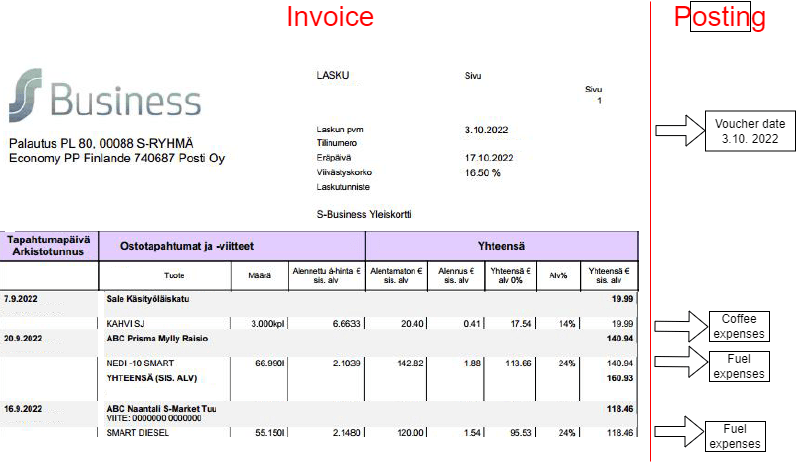
First, purchase invoice needs to be addressed to the proper bookkeeping account, i.e., to the right expense group. Expenses can be for example “Vehicle expenses” or very specific ones such as “Coffee expenses”. This is a multiclass classification problem where the number of classes are several hundreds. The classes can be even overlapping in a special way, for example “Vehicle expenses” and “Fuel expenses”. This leads to partial labeled learning that is the topic of the next blog in this series.
Second machine learning problem is to address the expense to a proper date to keep bookkeeping correct. This is an interesting problem as well as it can be formulated as machine learning problem in numerous different ways.
Both problems are supervised learning problems where we can utilize the earlier accounted invoices. However, after AI system has accounted invoices, we do not have any more independently labeled training data. Here active learning comes to play that is topic of the third blog in the series.
Whenever human does not anymore validate every single decision machine has made, it is crucial to know that the machine is reliable. In machine learning it is typical that the machine finds some random correlation between some feature and target variable in the training set. The same correlation may be even in the validation set when the machine learning model is validated. However, some day data distribution in production changes and the correlation disappears. Then the machine starts to make wrong decisions. In this case there was correlation between the feature and target variable but not a real causal relationship. How can we detect and avoid it? Explainable AI is a set of different methods for this kind of scenario. We cover it in our last blog of the series.

